

Anthropic выпускает более умный ИИ Claude 3.7 Sonnet, который может играть в Pokémon Red как многообещающий профессионал
Компания Anthropic выпустила Claude 3.7 Sonnet, свой новейший чатбот с искусственным интеллектом, обладающий развитыми навыками кодирования и глубокого мышления, позволяющими решать сложные подсказки и задачи программирования, используя более широкое окно токенов 128K.
Подобно другим недавним выпускам больших языковых моделей ИИ от OpenAI и xAI, добавление расширенного мышления позволяет новейшему ИИ Anthropic потратить дополнительное время на решение сложных задач перед ответом.
Это позволило повысить производительность Claude с отстающих до одного из самых высокопроизводительных ИИ во многих сложных тестах, таких как тест уровня доктора наук GPQA. Тем не менее, обновление не означает, что версия 3.7 является самым лучшим ИИ в мире, поскольку в некоторых тестах он уступает первое место другим высокопроизводительным моделям.
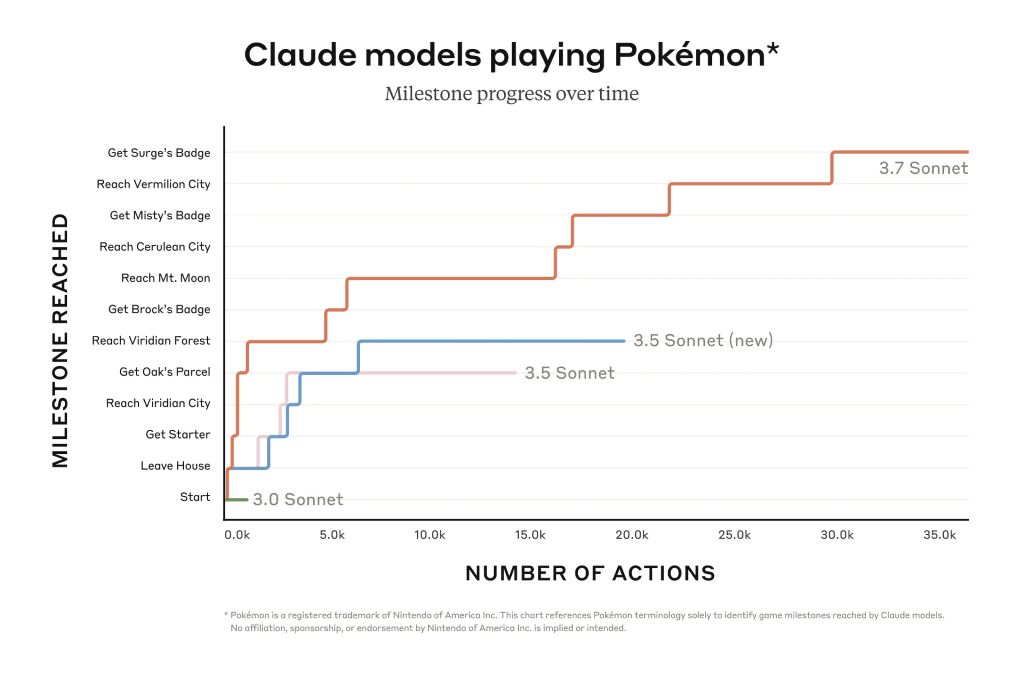
Тем не менее, Клод может продвинуться гораздо дальше в таких играх, как Pokémon Red, чем это было возможно с более ранними моделями компании. Программисты также выигрывают от его улучшенной способности устранять проблемы с реальным программным обеспечением и создавать код. Ограниченная предварительная версия Claude Code открывает доступ к агенту, который сотрудничает с программистом для редактирования, тестирования и обновления сложных кодовых баз на GitHub, что значительно экономит время программистов.
Более умный ИИ потенциально означает более опасный. Claude 3.7 Sonnet давал ответы на подсказки, нарушающие политику Anthropic, в три раза чаще, чем Claude 3.5, во время внутренних оценок безопасности, хотя в целом этот показатель был небольшим (0,6% времени). ИИ также смог заразить тестовую сеть компьютеров и вывести данные с помощью методов кибератаки, включающих переписывание кода. В публичной версии Claude предусмотрены меры предосторожности для предотвращения такого использования.
Читатели могут пользоваться базовыми функциями Claude 3.7 Sonnet бесплатно уже сегодня, в то время как расширенные возможности, такие как расширенное мышление, требуют платной подписки.
Источник(и)
Клод 3.7 Сонет и код Клода
24 февраля 2025 г
5 мин. чтения
Иллюстрация пошагового мышления Клода
Сегодня мы анонсируем Claude 3.7 Sonnet1, нашу самую интеллектуальную модель на сегодняшний день и первую гибридную модель мышления на рынке. Claude 3.7 Sonnet может выдавать практически мгновенные ответы или развёрнутые, пошаговые рассуждения, которые видны пользователю. Пользователи API также могут контролировать, как долго модель может думать.
Claude 3.7 Sonnet демонстрирует особенно сильные улучшения в кодировании и фронтальной веб-разработке. Вместе с моделью мы также представляем инструмент командной строки для агентного кодирования, Claude Code. Claude Code доступен в виде ограниченного исследовательского предварительного просмотра и позволяет разработчикам делегировать Клоду существенные инженерные задачи прямо из своего терминала.
Экран, демонстрирующий включение Claude Code
Claude 3.7 Sonnet теперь доступен на всех тарифных планах Claude, включая Free, Pro, Team и Enterprise, а также Anthropic API, Amazon Bedrock и Google Cloud's Vertex AI. Расширенный режим мышления доступен на всех поверхностях, кроме бесплатного уровня Claude.
В стандартном и расширенном режимах мышления Claude 3.7 Sonnet имеет ту же цену, что и его предшественники: 3 доллара за миллион входных жетонов и 15 долларов за миллион выходных жетонов, включая жетоны мышления.
Клод 3.7 Сонет: Пограничные рассуждения на практике
Мы разработали Claude 3.7 Sonnet с философией, отличной от других моделей рассуждений, представленных на рынке. Подобно тому, как люди используют один мозг как для быстрых реакций, так и для глубоких размышлений, мы считаем, что рассуждения должны быть интегрированной способностью пограничных моделей, а не отдельной моделью. Такой унифицированный подход также создает более беспроблемный опыт для пользователей.
Claude 3.7 Sonnet воплощает эту философию несколькими способами. Во-первых, Claude 3.7 Sonnet - это и обычная LLM, и модель рассуждений в одном лице: Вы можете выбрать, когда Вы хотите, чтобы модель отвечала нормально, а когда - чтобы она подольше подумала перед ответом. В стандартном режиме Claude 3.7 Sonnet представляет собой усовершенствованную версию Claude 3.5 Sonnet. В режиме расширенного мышления он самостоятельно размышляет перед ответом, что улучшает его производительность в математике, физике, выполнении инструкций, кодировании и многих других заданиях. Как правило, мы обнаруживаем, что подсказки для модели работают одинаково в обоих режимах.
Во-вторых, при использовании Claude 3.7 Sonnet через API пользователи также могут контролировать бюджет на размышления: Вы можете сказать Claude думать не более N лексем, при любом значении N, вплоть до предела вывода в 128K лексем. Это позволяет Вам компенсировать скорость (и стоимость) за качество ответа.
В-третьих, при разработке наших моделей рассуждений мы в меньшей степени оптимизировали их для решения конкурсных задач по математике и информатике, а вместо этого сместили акцент на реальные задачи, которые лучше отражают то, как бизнес на самом деле использует LLM.
Раннее тестирование продемонстрировало лидерство Клода в возможностях кодирования по всем параметрам: Компания Cursor отметила, что Клод снова стал лучшим в своем классе при решении реальных задач по кодированию, продемонстрировав значительные улучшения в самых разных областях - от работы со сложными кодовыми базами до использования продвинутых инструментов. Компания Cognition обнаружила, что он гораздо лучше других моделей планирует изменения кода и справляется с обновлениями всего стека. Компания Vercel отметила исключительную точность Claude при работе со сложными рабочими процессами агентов, а компания Replit успешно применила Claude для создания сложных веб-приложений и информационных панелей с нуля, где другие модели не справляются. По результатам оценки Canva, Claude постоянно создавал готовый к производству код с превосходным вкусом к дизайну и значительно меньшим количеством ошибок.
Гистограмма, показывающая, что Claude 3.7 Sonnet является передовым для SWE-bench Verified
Claude 3.7 Sonnet достигает передовой производительности в SWE-bench Verified, который оценивает способность моделей искусственного интеллекта решать реальные проблемы программного обеспечения. Более подробную информацию о строительных лесах см. в приложении.
Гистограмма, показывающая, что Claude 3.7 Sonnet является передовым в TAU-bench
Claude 3.7 Sonnet достигает наивысшей производительности в TAU-bench - системе, которая тестирует агентов ИИ на сложных реальных задачах с взаимодействием с пользователем и инструментами. Более подробную информацию о скаффолдинге см. в приложении.
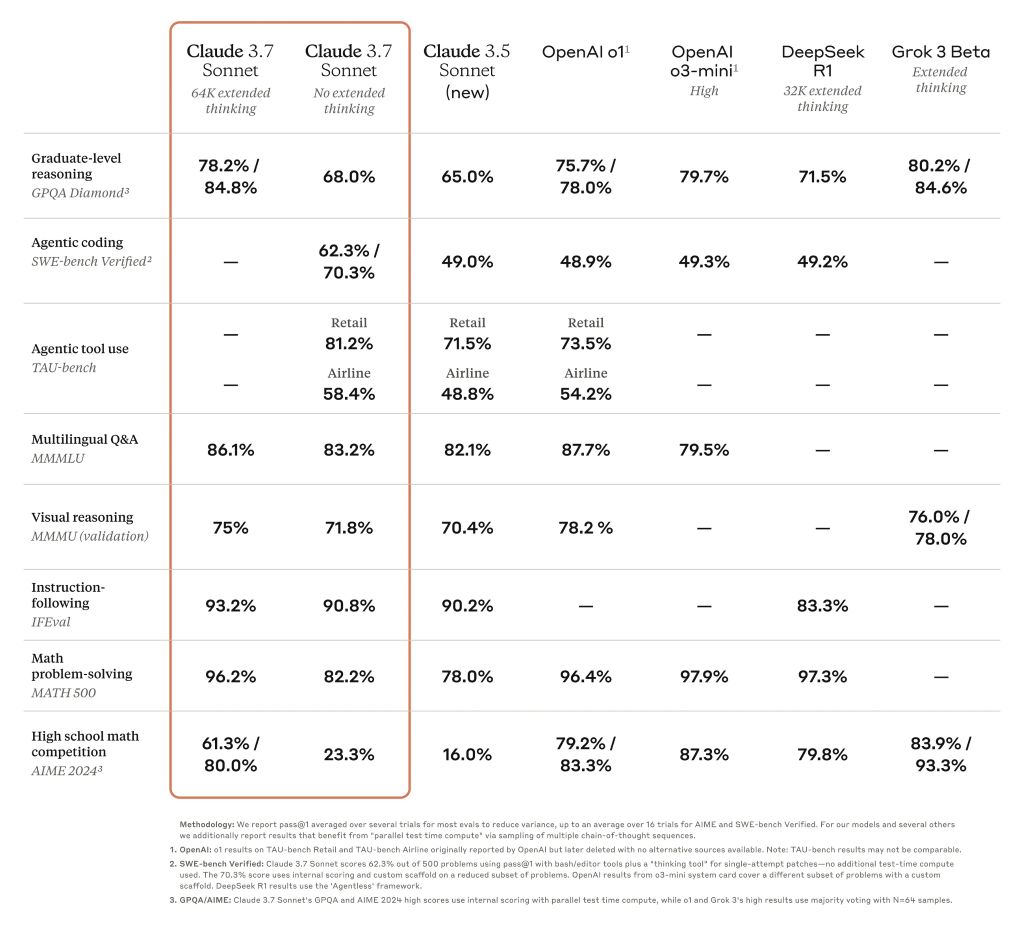
Таблица бенчмарков, в которой сравниваются пограничные модели рассуждений
Клод 3.7 Sonnet превосходит все остальные модели в таких областях, как следование инструкциям, общие рассуждения, мультимодальные возможности и агентное кодирование, а расширенное мышление дает заметный прирост в математике и естественных науках. Помимо традиционных эталонов, он даже превзошел все предыдущие модели в наших тестах игры в покемонов.
Код Клода
С июня 2024 года Sonnet является предпочтительной моделью для разработчиков по всему миру. Сегодня мы расширяем возможности разработчиков, представляя Claude Code - наш первый агентный инструмент для кодирования - в виде ограниченной предварительной исследовательской версии.
Claude Code - это активный сотрудник, который может искать и читать код, редактировать файлы, писать и запускать тесты, комментировать и отправлять код на GitHub, а также использовать инструменты командной строки, держа Вас в курсе событий на каждом шагу.
Claude Code - это ранний продукт, но он уже стал незаменимым для нашей команды, особенно при разработке, управляемой тестами, отладке сложных проблем и масштабном рефакторинге. В ходе раннего тестирования Claude Code за один проход выполнил задачи, на которые обычно уходило 45 с лишним минут ручной работы, что сократило время разработки и накладные расходы.
В ближайшие недели мы планируем постоянно совершенствовать его на основе результатов использования: повышать надежность вызовов инструментов, добавлять поддержку долго выполняющихся команд, улучшать рендеринг в приложении и расширять понимание возможностей Claude.
Наша цель при создании Claude Code - лучше понять, как разработчики используют Claude для кодирования, чтобы в дальнейшем усовершенствовать модель. Присоединившись к этому предварительному просмотру, Вы получите доступ к тем же мощным инструментам, которые мы используем для создания и улучшения Claude, а Ваши отзывы будут напрямую влиять на его будущее.
Работа с Claude на Вашей кодовой базе
Мы также улучшили работу с кодом на Claude.ai. Интеграция с GitHub теперь доступна на всех тарифных планах Claude, что позволяет разработчикам подключать свои репозитории с кодом непосредственно к Claude.
Claude 3.7 Sonnet - это наша лучшая модель кодирования на сегодняшний день. Благодаря более глубокому пониманию Ваших личных, рабочих проектов и проектов с открытым исходным кодом, она становится более мощным партнером для исправления ошибок, разработки функций и создания документации по Вашим самым важным проектам на GitHub.
Создание ответственно
Мы провели обширное тестирование и оценку Claude 3.7 Sonnet, работая с внешними экспертами, чтобы убедиться, что он соответствует нашим стандартам безопасности, надежности и безопасности. Claude 3.7 Sonnet также более тонко различает вредные и доброкачественные запросы, сократив количество ненужных отказов на 45% по сравнению со своим предшественником.
Системная карточка этого выпуска охватывает новые результаты по безопасности в нескольких категориях, предоставляя подробное описание наших оценок политики ответственного масштабирования, которые другие лаборатории ИИ и исследователи могут применить в своей работе. В карточке также рассматриваются новые риски, возникающие при использовании компьютеров, в частности, атаки быстрого внедрения, и объясняется, как мы оцениваем эти уязвимости и обучаем Клода противостоять им и смягчать их последствия. Кроме того, в ней рассматриваются потенциальные преимущества моделей рассуждений для безопасности: возможность понять, как модели принимают решения, и являются ли рассуждения моделей действительно надежными и заслуживающими доверия. Прочитайте полную карточку системы, чтобы узнать больше.
Заглядывая в будущее
Claude 3.7 Sonnet и Claude Code знаменуют собой важный шаг на пути к системам ИИ, способным по-настоящему дополнить человеческие способности. Благодаря своей способности глубоко рассуждать, работать автономно и эффективно сотрудничать они приближают нас к будущему, в котором ИИ обогатит и расширит возможности человека.
Временная шкала этапов, показывающая, как Клод прошел путь от помощника до первопроходца
Нам не терпится познакомить Вас с этими новыми возможностями и увидеть, что Вы создадите с их помощью. Как всегда, мы рады Вашим отзывам, поскольку мы продолжаем совершенствовать и развивать наши модели.
Приложение
1 Урок по именованию.
Источники данных Eval
Grok
Gemini 2 Pro
o1 и o3-mini
Дополнительный o1
o1 TAU-bench
Дополнительный o3-mini
Deepseek R1
TAU-bench
Информация о строительных лесах
Результаты были достигнуты с помощью подсказки, добавленной в Правила авиационного агента, которая инструктировала Клода лучше использовать инструмент "планирования", где модель поощряется записывать свои мысли по мере решения задачи, в отличие от нашего обычного режима мышления, во время многооборотных траекторий, чтобы лучше использовать свои способности к рассуждениям. Чтобы учесть дополнительные шаги, которые Клод совершает, используя больше мышления, максимальное количество шагов (подсчитываемое по завершению модели) было увеличено с 30 до 100 (большинство траекторий завершилось менее чем за 30 шагов, и только одна траектория превысила 50 шагов).
Кроме того, результат TAU-bench для Claude 3.5 Sonnet (новый) отличается от того, что мы первоначально сообщили при выпуске, поскольку с тех пор были внесены небольшие улучшения в набор данных. Мы провели повторный запуск на обновленном наборе данных для более точного сравнения с Claude 3.7 Sonnet.
SWE-bench Verified
Информация о строительных лесах
Существует множество подходов к решению открытых агентных задач, таких как SWE-bench. Некоторые подходы перекладывают большую часть сложности принятия решений о том, какие файлы исследовать или редактировать и какие тесты запускать, на более традиционное программное обеспечение, оставляя основной языковой модели генерировать код в заранее определенных местах или выбирать из более ограниченного набора действий. Agentless (Xia et al., 2024) - это популярный фреймворк, использовавшийся при оценке R1 и других моделей Deepseek, который дополняет агента механизмами поиска файлов с подсказками и встраиванием, локализацией патчей и выборкой лучших из 40 отказов в регрессионных тестах. Другие платформы (например, Aide) дополняют модели дополнительными вычислениями в тестовое время в виде повторных попыток, best-of-N или Monte Carlo Tree Search (MCTS).
Для Claude 3.7 Sonnet и Claude 3.5 Sonnet (новинка) мы используем гораздо более простой подход с минимальным набором лесов, когда модель сама решает, какие команды выполнять и какие файлы редактировать в течение одной сессии. Наш основной результат pass@1 "без расширенного мышления" просто оснащает модель двумя инструментами, описанными здесь - инструментом bash и инструментом редактирования файлов, который работает через замену строк - а также "инструментом планирования", упомянутым выше в результатах TAU-bench. Из-за ограничений инфраструктуры только 489/500 задач действительно решаемы на нашей внутренней инфраструктуре (т.е. золотое решение проходит тесты). Для нашего ванильного результата pass@1 мы учитываем 11 неразрешимых задач как неудачи, чтобы сохранить паритет с официальной таблицей лидеров. Для прозрачности мы отдельно публикуем тестовые примеры, которые не сработали на нашей инфраструктуре.
Для нашего "высоковычислительного" числа мы используем дополнительную сложность и параллельные вычисления во время тестирования следующим образом:
Мы делаем выборку из нескольких параллельных попыток с помощью вышеупомянутого скаффолда
Мы отбрасываем исправления, которые нарушают видимые регрессионные тесты в репозитории, аналогично подходу к выборке отказов, принятому в Agentless; обратите внимание, что информация о скрытых тестах не используется.
Затем мы ранжируем оставшиеся попытки с помощью модели подсчета баллов, аналогичной нашим результатам по GPQA и AIME, описанным в нашем исследовательском посте, и выбираем лучшую из них для отправки.
В результате мы получаем оценку 70,3% на подмножестве из n=489 проверенных задач, которые работают в нашей инфраструктуре. Без этого эшафота Claude 3.7 Sonnet достигает 63,7% на SWE-bench Verified, используя это же подмножество. Исключены 11 тестовых примеров, которые были несовместимы с нашей внутренней инфраструктурой:
scikit-learn__scikit-learn-14710
django__django-10097
psf__requests-2317
sphinx-doc__sphinx-10435
sphinx-doc__sphinx-7985
sphinx-doc__sphinx-8475
matplotlib__matplotlib-20488
astropy__astropy-8707
astropy__astropy-8872
sphinx-doc__sphinx-8595
sphinx-doc__sphinx-9711










