

Meta представляет самый большой, самый умный, безвозмездный ИИ Llama 3.1 405B

Компания Meta представила свой ИИ Llama 3.1 405B для безвозмездного использования. Большая языковая модель (LLM) объемом 750 Гб и 405 миллиардами параметров является одной из самых больших из когда-либо выпущенных, что позволяет ей конкурировать с такими флагманами ИИ, как Anthropic Claude 3.5 Sonnet, благодаря расширенному окну ввода 128K лексем и OpenAI GPT-4o. В отличие от платных конкурентов с закрытым исходным кодом, читатели могут настроить и запустить бесплатный LLM на своих собственных компьютерах, оснащенных чрезвычайно мощными графическими картами (GPU) Nvidia.
Творчество и энергия
Meta задействовала до 16 384 700W TDP Графических процессоров H100 на серверной платформе Meta Grand Teton AI, чтобы произвести 3,8 x 10^25 FLOP, необходимых для создания модели с 405 миллиардами параметров на 16,55 триллионах токенов (1000 токенов - это примерно 750 слов). Сбои, связанные с GPU, привели к 57,3% простоев во время предварительного обучения, причем 30,1% были вызваны неисправными GPU.
Более 54 дней ушло на предварительное обучение ИИ на документах, в общей сложности 39,3 миллиона часов работы GPU было использовано для обучения Llama 3.1 405B. По быстрым подсчетам, потребление электроэнергии во время обучения составило более 11 ГВт-ч, при этом было выброшено 11 390 тонн парниковых газов в CO2-эквиваленте.
Безопасность и производительность
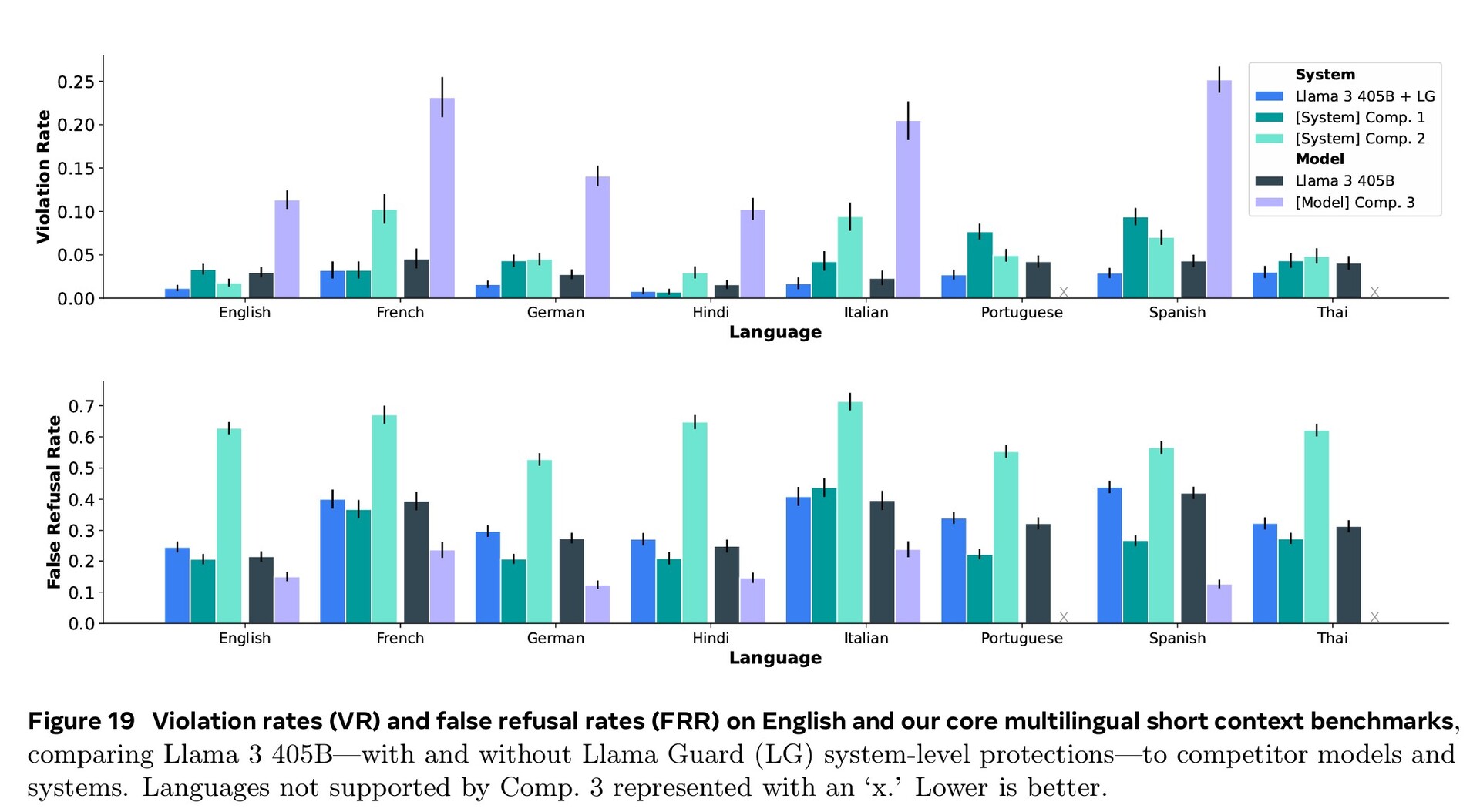
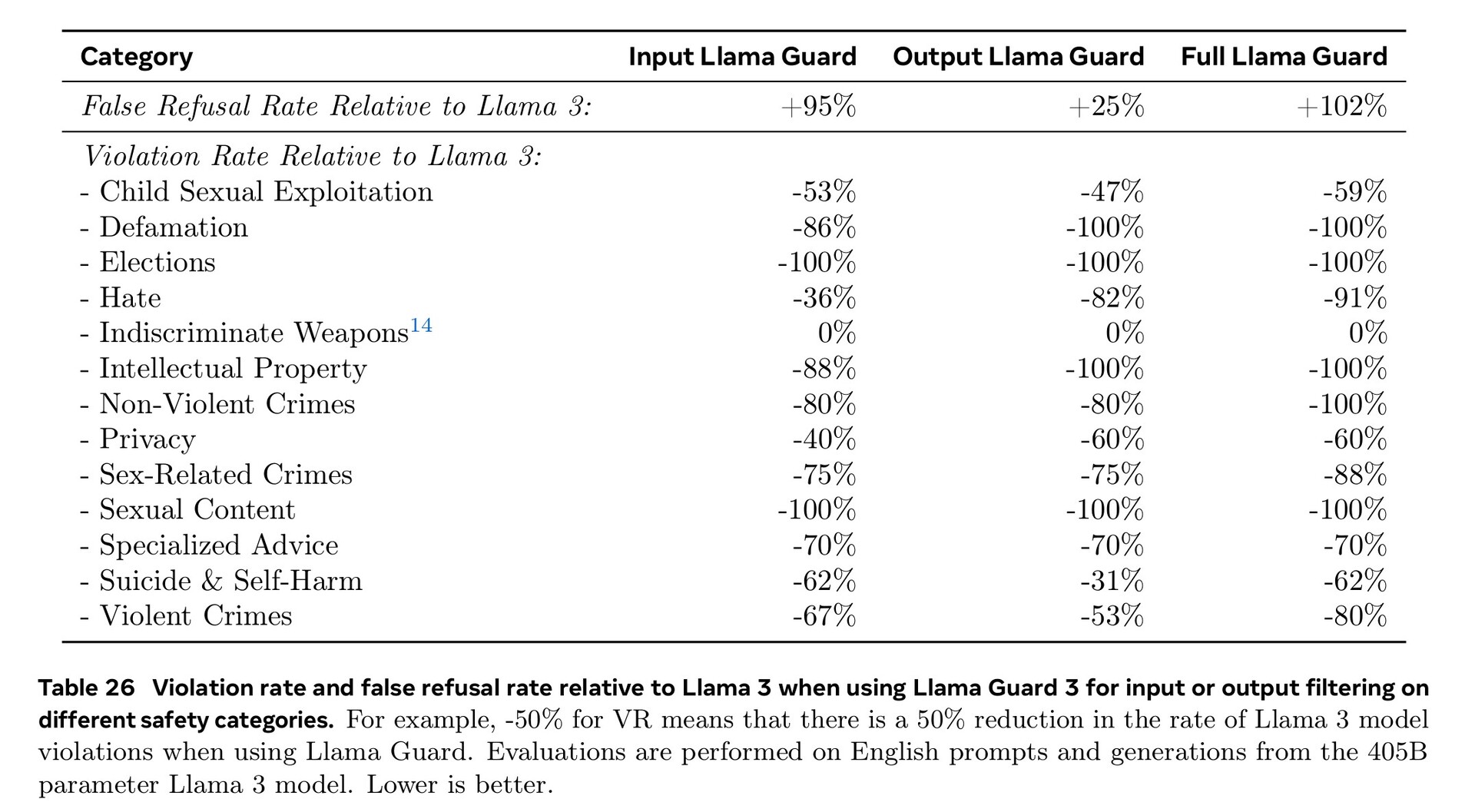
Обширное обучение в таких областях, как кибербезопасность, безопасность детей, химические и биологические атаки, оперативные инъекции и многое другое, а также фильтрация входного и выходного текста с помощью Llama Guard 3 позволили добиться лучших показателей безопасности по сравнению с конкурирующими моделями ИИ. Тем не менее, меньшее количество документов на иностранных языках, доступных для обучения, означает, что Llama 3.1 с большей вероятностью ответит на опасные вопросы на португальском или французском, чем на английском.
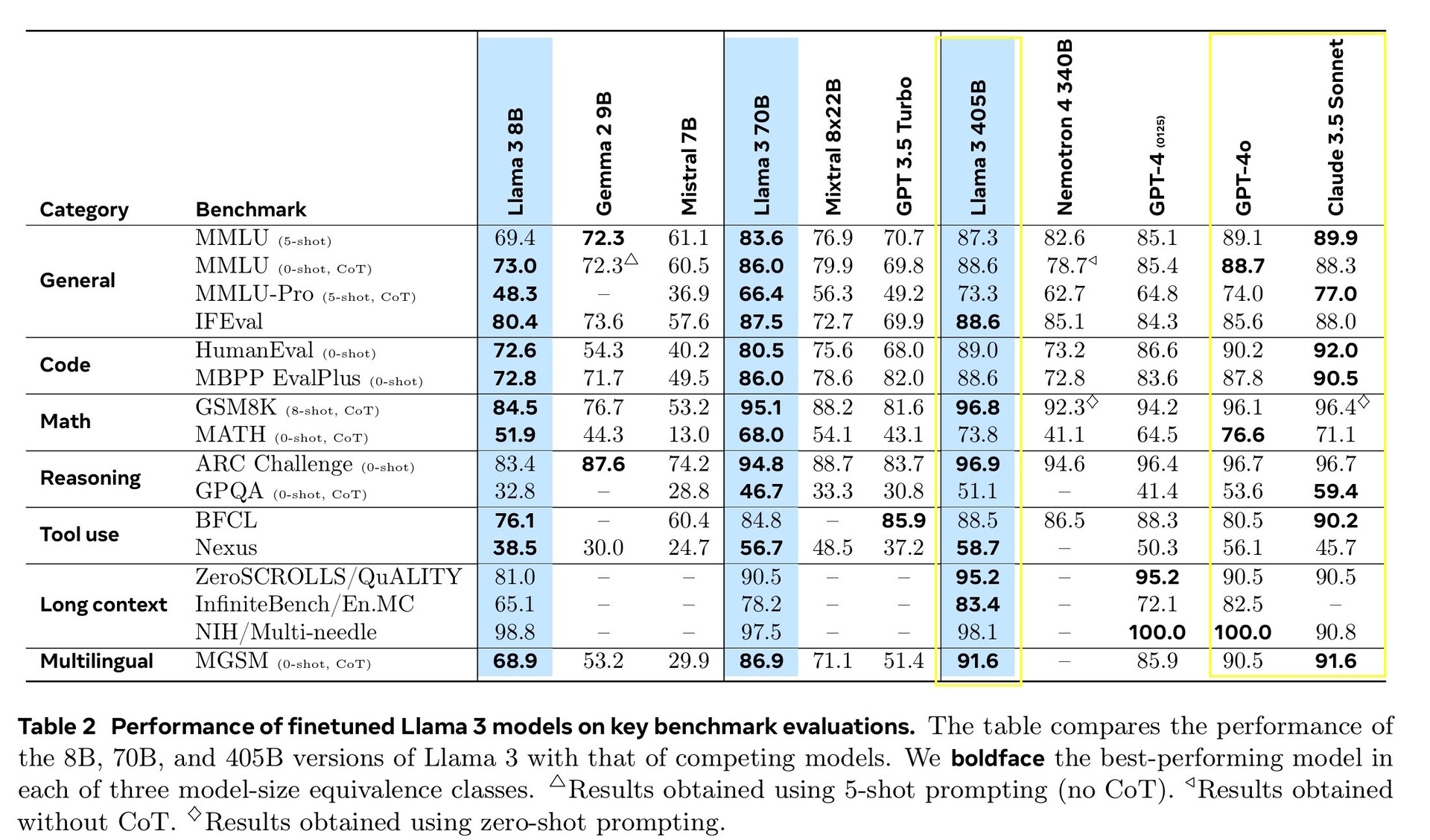
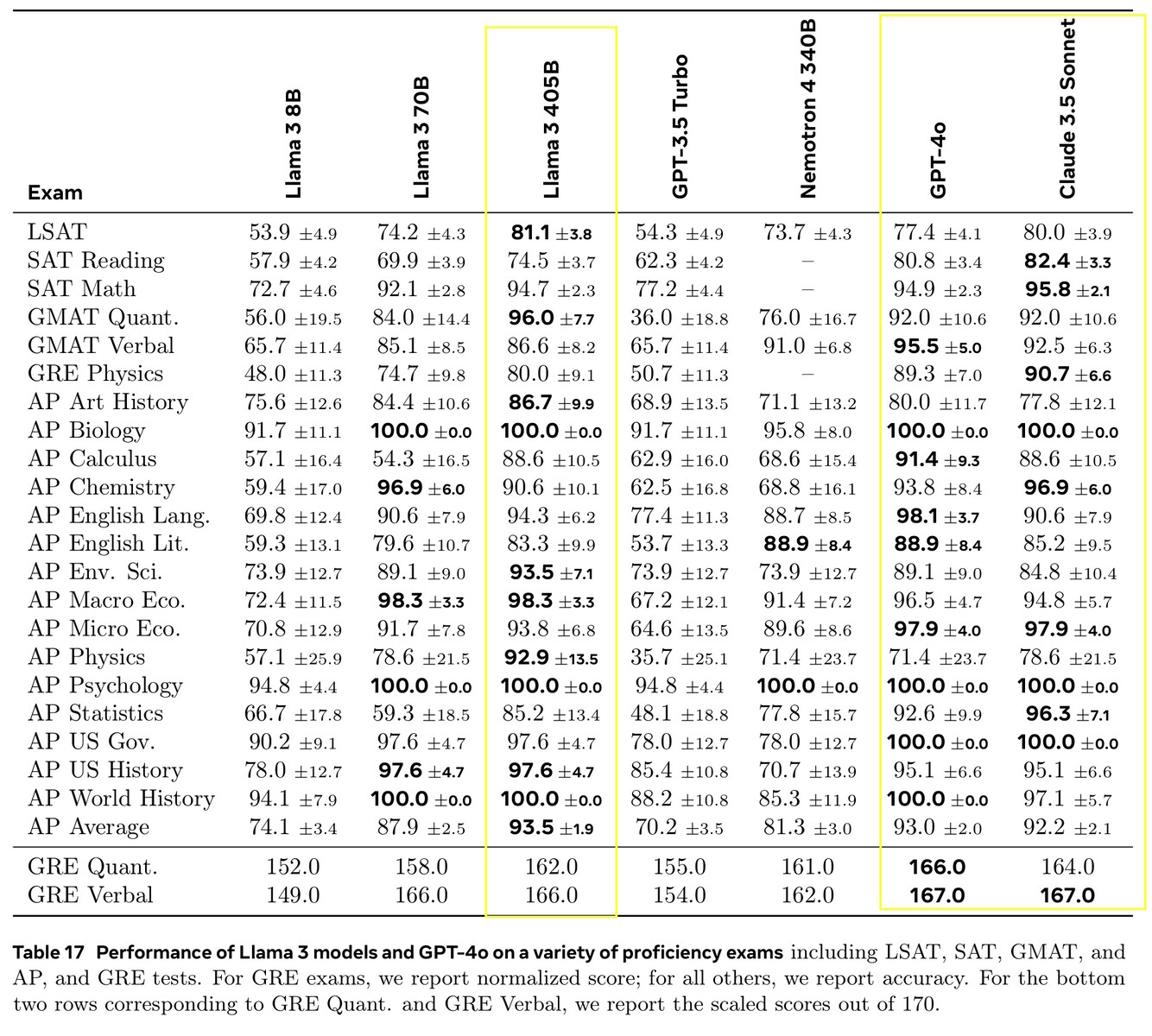
Llama 3.1 405B набрала от 51,1 до 96,6% баллов в тестах ИИ на уровне колледжа и выпускников, что соответствует Claude 3.5 Sonnet и GPT-4o. В реальных тестах, оцениваемых людьми, GPT-4o давал лучшие ответы на 52,9% чаще, чем Llama. Модель ничего не знает за пределами даты отсечения знаний в декабре 2023 года, но она может собирать самую свежую информацию в Интернете с помощью Brave Search, решать математические задачи с помощью Wolfram Alphaи решать проблемы кодирования в интерпретаторе Python https://www.python.org/.
Требования
Исследователям, заинтересованным в локальном запуске Llama 3.1 405B, потребуются очень мощные компьютеры с 750 Гб свободного места для хранения данных. Для запуска полной модели потребуется восемь Графических процессоров Nvidia A100 или аналогичных, обеспечивающих два узла MP16 и 810 ГБ VRAM GPU для выводов, в системе с 1 ТБ ОЗУ. Meta выпустила более компактные версии, которые требуют меньше ресурсов, но работают хуже: Llama 3.1 8B и 70B. Llama 3.1 8B требуется всего 16 ГБ VRAM на GPU, поэтому она отлично работает на хорошо оснащенном Nvidia 4090(как этот ноутбук на Amazon) примерно на уровне GPT-3.5 Turbo. Читатели, которые просто хотят использовать лучший ИИ, могут установить такое приложение, как Anthropic's Android или приложение для iOS.
Источник(и)
Большая языковая модель
Представляем вам Llama 3.1: Наши самые мощные модели на сегодняшний день
23 июля 2024 г
15 минут чтения
Выводы:
Meta стремится к открытому доступу к ИИ. Прочитайте письмо Марка Цукерберга, в котором он подробно объясняет, почему открытый исходный код хорош для разработчиков, хорош для Meta и хорош для всего мира.
Чтобы сделать открытый интеллект доступным для всех, наши последние модели увеличивают длину контекста до 128K, добавляют поддержку восьми языков и включают Llama 3.1 405B - первую модель ИИ с открытым исходным кодом пограничного уровня.
Llama 3.1 405B находится в своем собственном классе, обладая непревзойденной гибкостью, контролем и самыми современными возможностями, которые соперничают с лучшими моделями с закрытым исходным кодом. Наша новая модель позволит сообществу открыть новые рабочие процессы, такие как генерация синтетических данных и дистилляция моделей.
Мы продолжаем развивать Llama как систему, предоставляя все больше компонентов, работающих с моделью, включая эталонную систему. Мы хотим предоставить разработчикам инструменты для создания собственных агентов и новых типов агентского поведения. Мы подкрепляем это новыми инструментами безопасности и защиты, включая Llama Guard 3 и Prompt Guard, чтобы помочь разработчикам строить ответственно. Мы также публикуем запрос на комментарии по Llama Stack API - стандартному интерфейсу, который, как мы надеемся, облегчит сторонним проектам использование моделей Llama.
Экосистема уже готова к работе: более 25 партнеров, включая AWS, NVIDIA, Databricks, Groq, Dell, Azure, Google Cloud и Snowflake, предлагают свои услуги с первого дня.
Попробуйте Llama 3.1 405B в США в WhatsApp и на сайте meta.ai, задав сложный вопрос по математике или кодированию.
РЕКОМЕНДУЕМАЯ ЛИТЕРАТУРА
Расширение экосистемы Llama с ответственностью
Экосистема Llama: Прошлое, настоящее и будущее
До сегодняшнего дня большие языковые модели с открытым исходным кодом в основном отставали от своих закрытых аналогов, когда речь шла о возможностях и производительности. Теперь мы начинаем новую эру, в которой ведущую роль играет открытый исходный код. Мы публично выпускаем Meta Llama 3.1 405B, которая, по нашему мнению, является самой большой и самой мощной в мире моделью с открытым исходным кодом. С учетом того, что на сегодняшний день все версии Llama скачали более 300 миллионов раз, мы только начинаем.
Представляем Llama 3.1
Llama 3.1 405B - это первая открытая модель, которая соперничает с лучшими моделями ИИ, когда речь идет о самых современных возможностях в области общих знаний, управляемости, математики, использования инструментов и многоязычного перевода. Выпустив модель 405B, мы готовы дать толчок инновациям, открыв беспрецедентные возможности для роста и исследований. Мы считаем, что последнее поколение Llama зажжет новые приложения и парадигмы моделирования, включая генерацию синтетических данных для улучшения и обучения более мелких моделей, а также дистилляцию моделей - возможности, которые никогда не были достигнуты в таком масштабе в открытом исходном коде.
В рамках этого последнего выпуска мы представляем обновленные версии моделей 8B и 70B. Они многоязычны, имеют значительно большую длину контекста (128K), используют самые современные инструменты и обладают более широкими возможностями для рассуждений. Это позволяет нашим новейшим моделям поддерживать расширенные варианты использования, такие как резюмирование длинных текстов, многоязычные разговорные агенты и ассистенты кодирования. Мы также внесли изменения в нашу лицензию, позволяющие разработчикам использовать результаты моделей Llama, включая 405B, для улучшения других моделей. Верные нашим обязательствам по открытому исходному коду, начиная с сегодняшнего дня, мы предоставляем эти модели сообществу для загрузки на сайтах llama.meta.com и Hugging Face, а также для немедленной разработки на нашей широкой экосистеме партнерских платформ.
Оценки моделей
В этом выпуске мы оценили производительность на более чем 150 эталонных наборах данных, которые охватывают широкий спектр языков. Кроме того, мы провели обширную оценку на людях, сравнивая Llama 3.1 с конкурирующими моделями в реальных сценариях. Наша экспериментальная оценка показала, что наша флагманская модель конкурентоспособна с ведущими базовыми моделями в ряде задач, включая GPT-4, GPT-4o и Claude 3.5 Sonnet. Кроме того, наши небольшие модели конкурентоспособны с закрытыми и открытыми моделями, имеющими схожее количество параметров.
Архитектура модели
Обучение Llama 3.1 405B на более чем 15 триллионах лексем стало серьезной задачей для нашей самой большой модели. Чтобы провести обучение в таком масштабе и достичь результатов за разумное время, мы значительно оптимизировали весь стек обучения и перевели обучение модели на более чем 16 тысяч графических процессоров H100, сделав 405B первой моделью Llama, обученной в таком масштабе.
Чтобы решить эту проблему, мы сделали выбор, направленный на то, чтобы процесс разработки модели был масштабируемым и простым.
Мы выбрали стандартную архитектуру модели, состоящую только из декодера и трансформатора, с небольшими изменениями, а не модель "смесь экспертов", чтобы обеспечить максимальную стабильность обучения.
Мы приняли итеративную процедуру посттренинга, где в каждом раунде используется контролируемая тонкая настройка и прямая оптимизация предпочтений. Это позволило нам создавать синтетические данные высочайшего качества для каждого раунда и улучшать производительность каждой возможности.
По сравнению с предыдущими версиями Llama, мы улучшили количество и качество данных, которые мы используем для предварительного и последующего обучения. Эти улучшения включают в себя разработку более тщательной предварительной обработки и конвейеров курирования для данных предварительного обучения, а также разработку более строгих подходов к обеспечению качества и фильтрации для данных пост-обучения.
Как и ожидалось в соответствии с законами масштабирования для языковых моделей, наша новая флагманская модель превзошла более мелкие модели, обученные по той же процедуре. Мы также использовали модель с параметрами 405B для улучшения качества пост-обучения наших меньших моделей.
Чтобы поддержать крупномасштабное производство выводов для модели масштаба 405B, мы квантовали наши модели с 16-битных (BF16) до 8-битных (FP8) численных данных, эффективно снизив необходимые вычислительные требования и позволив модели работать на одном серверном узле.
Тонкая настройка инструкций и чатов
В Llama 3.1 405B мы стремились улучшить полезность, качество и способность модели выполнять подробные инструкции в ответ на указания пользователя, обеспечивая при этом высокий уровень безопасности. Нашими самыми большими проблемами были поддержка большего количества возможностей, контекстное окно 128K и увеличение размеров модели.
В процессе пост-обучения мы создаем окончательные модели чата, выполняя несколько раундов выравнивания поверх предварительно обученной модели. Каждый раунд включает в себя Supervised Fine-Tuning (SFT), Rejection Sampling (RS) и Direct Preference Optimization (DPO). Мы используем синтетические данные для создания подавляющего большинства наших примеров SFT, многократно повторяя итерации для получения синтетических данных все более высокого качества по всем параметрам. Кроме того, мы инвестируем в различные методы обработки данных, чтобы отфильтровать эти синтетические данные до наивысшего качества. Это позволяет нам масштабировать количество данных для тонкой настройки по всем возможностям.
Мы тщательно балансируем данные, чтобы создать модель с высоким качеством для всех возможностей. Например, мы сохраняем качество нашей модели на эталонах с коротким контекстом даже при расширении до 128K контекста. Аналогично, наша модель продолжает давать максимально полезные ответы, даже когда мы добавляем меры по снижению безопасности.
Система Llama
Модели Llama всегда должны были работать как часть общей системы, которая может управлять несколькими компонентами, включая вызов внешних инструментов. Мы хотим выйти за рамки базовых моделей и предоставить разработчикам доступ к более широкой системе, которая обеспечит им гибкость в разработке и создании индивидуальных предложений, соответствующих их видению. Мысль об этом зародилась в прошлом году, когда мы впервые представили возможность включения компонентов за пределами основного LLM.
В рамках наших постоянных усилий по ответственной разработке ИИ за пределами слоя модели и помощи другим в этом, мы выпускаем полную эталонную систему, включающую несколько примеров приложений и новые компоненты, такие как Llama Guard 3, многоязычная модель безопасности, и Prompt Guard, фильтр инъекций подсказок. Эти примеры приложений имеют открытый исходный код и могут быть доработаны сообществом.
Реализация компонентов этой концепции системы Llama все еще фрагментарна. Поэтому мы начали работать с промышленностью, стартапами и широким сообществом, чтобы помочь лучше определить интерфейсы этих компонентов. Чтобы поддержать эту работу, мы публикуем на GitHub запрос на комментарии к тому, что мы называем "Llama Stack" Llama Stack - это набор стандартизированных и согласованных интерфейсов для создания канонических компонентов цепочки инструментов (тонкая настройка, генерация синтетических данных) и агентных приложений. Мы надеемся, что они станут общепринятыми в экосистеме, что поможет упростить взаимодействие.
Мы приветствуем отзывы и способы улучшить это предложение. Нам не терпится развить экосистему вокруг Llama и снизить барьеры для разработчиков и поставщиков платформ.
Открытость стимулирует инновации
В отличие от закрытых моделей, весовые коэффициенты моделей Llama доступны для скачивания. Разработчики могут полностью настроить модели под свои нужды и приложения, тренироваться на новых наборах данных и проводить дополнительную тонкую настройку. Таким образом, сообщество разработчиков и весь мир смогут в полной мере оценить возможности генеративного ИИ. Разработчики могут полностью адаптировать модели для своих приложений и запускать их в любой среде, в том числе на предприятии, в облаке или даже локально на ноутбуке - и все это без передачи данных компании Meta.
Хотя многие могут утверждать, что закрытые модели более экономически эффективны, модели Llama предлагают одну из самых низких стоимостей на токен в отрасли, согласно результатам тестирования, проведенного компанией Artificial Analysis. Как отметил Марк Цукерберг, открытый исходный код обеспечит доступ большего количества людей по всему миру к преимуществам и возможностям ИИ, позволит не концентрировать власть в руках немногих, а также обеспечит более равномерное и безопасное внедрение технологии в обществе. Именно поэтому мы продолжаем делать шаги на пути к тому, чтобы ИИ с открытым доступом стал отраслевым стандартом.
Мы видели, как сообщество создавало удивительные вещи с помощью прошлых моделей Llama, включая ИИ-друга, созданного с помощью Llama и внедренного в WhatsApp и Messenger, LLM, адаптированный для медицины и помогающий принимать клинические решения, и некоммерческий стартап в области здравоохранения в Бразилии, который упрощает для системы здравоохранения организацию и передачу информации о госпитализации пациентов, причем все это в безопасном для данных виде. Нам не терпится увидеть, что они построят с помощью наших последних моделей благодаря силе открытого исходного кода.
Создание с помощью Llama 3.1 405B
Для обычного разработчика использование модели масштаба 405B является сложной задачей. Несмотря на то, что это невероятно мощная модель, мы понимаем, что для работы с ней требуются значительные вычислительные ресурсы и опыт. Мы пообщались с сообществом и поняли, что в разработке генеративного ИИ есть гораздо больше, чем просто модели подсказок. Мы хотим дать возможность каждому получить максимум от 405B, включая:
Выводы в реальном времени и в пакетном режиме
Тонкая настройка под наблюдением
Оценка модели для Вашего конкретного приложения
Постоянное предварительное обучение
Генерация с улучшенным извлечением (RAG)
Вызов функций
Генерация синтетических данных
Именно здесь экосистема Llama может помочь. В первый же день разработчики могут воспользоваться всеми расширенными возможностями модели 405B и сразу же приступить к созданию. Разработчики также могут изучить расширенные рабочие процессы, такие как простая в использовании генерация синтетических данных, следовать готовым инструкциям по дистилляции модели, а также использовать бесшовный RAG с решениями от партнеров, включая AWS, NVIDIA и Databricks. Кроме того, компания Groq оптимизировала вывод данных с низкой задержкой для развертывания в облаке, а компания Dell добилась аналогичной оптимизации для локальных систем.
Мы работали с ключевыми проектами сообщества, такими как vLLM, TensorRT и PyTorch, чтобы обеспечить поддержку с первого дня, чтобы сообщество было готово к производственному развертыванию.
Мы надеемся, что наш выпуск 405B также подстегнет инновации в более широком сообществе, чтобы сделать вывод и тонкую настройку моделей такого масштаба проще и обеспечить следующую волну исследований в области дистилляции моделей.
Попробуйте коллекцию моделей Llama 3.1 уже сегодня
Нам не терпится увидеть, что сообщество сделает с этой работой. Многоязычие и увеличенная длина контекста - это огромный потенциал для создания новых полезных ощущений. С помощью стека Llama и новых инструментов безопасности мы надеемся продолжить ответственное сотрудничество с сообществом разработчиков открытого кода. Прежде чем выпустить модель, мы работаем над выявлением, оценкой и снижением потенциальных рисков с помощью нескольких мер, включая упражнения по выявлению рисков перед развертыванием с помощью "красных команд" и тонкую настройку безопасности. Например, мы проводим обширную "красную команду" с внешними и внутренними экспертами, чтобы провести стресс-тестирование моделей и найти неожиданные способы их использования. (Подробнее о том, как мы ответственно подходим к масштабированию нашей коллекции моделей Llama 3.1, читайте в этом блоге)
Несмотря на то, что это наша самая большая модель, мы уверены, что в будущем нас ждет еще много нового, включая более удобные для устройств размеры, дополнительные модальности и больше инвестиций на уровне агентской платформы. Как всегда, мы с нетерпением ждем возможности увидеть все удивительные продукты и опыт, которые сообщество создаст с помощью этих моделей.
Эта работа была выполнена при поддержке наших партнеров из сообщества ИИ. Мы хотели бы поблагодарить и выразить признательность (в алфавитном порядке): Accenture, Amazon Web Services, AMD, Anyscale, CloudFlare, Databricks, Dell, Deloitte, Fireworks.ai, Google Cloud, Groq, Hugging Face, IBM WatsonX, Infosys, Intel, Kaggle, Microsoft Azure, NVIDIA, OctoAI, Oracle Cloud, PwC, Replicate, Sarvam AI, Scale.AI, SNCF, Snowflake, Together AI и проект vLLM, разработанный в Sky Computing Lab в Калифорнийском университете Беркли.



