

Утечка внутренней переписки показывает, что Nvidia ежедневно просматривает видео с YouTube в течение всей жизни, чтобы обучить модель ИИ для видео, и Дженсен доволен прогрессом

Компания Nvidia обучает свои Омниверсы, самодвижущиеся автомобили и "цифровых людей" на основе данных, взятых из "80-летнего объема видео в день" с YouTube и других источников, как показало расследование 404 Media.
Утечка внутренней переписки, полученная 404 Media, указывает на то, что Nvidia использует эти данные для обучения своей модели видеомира ИИ под названием Cosmos (не путать с существующим сервисом глубокого обучения компании Cosmos)). Внутри компании предполагается, что модель Cosmos станет основой для других направлений Nvidia, включая GeForce, архитектуру GPU, DGX, фреймворки Deep Learning, Omniverse, Avatar, Project GR00T и автономные транспортные средства.
Руководители Nvidia назвали Cosmos самой современной базовой моделью, "которая объединяет моделирование транспортировки света, физику и интеллект в одном месте, чтобы разблокировать различные последующие приложения, критически важные для Nvidia"
404 Media получила доступ к внутренним сообщениям сотрудников в Slack, из которых стало известно, как сотрудники использовали командную строку yt-dlp для загрузки видео с YouTube с помощью 20-30 виртуальных машин AWS, которые обновляли IP-адреса, чтобы избежать блокировки со стороны YouTube. Сайт обмена видео был основным источником для скачивания видео, но сотрудники также рассматривали и другие источники, такие как Netflix и Discovery Channel.
В переписке в Slack видно, как сотрудники обсуждают юридические последствия использования защищенного авторским правом контента для обучения искусственного интеллекта, но руководители проекта отвергают их как решение руководства, о котором им не стоит беспокоиться.
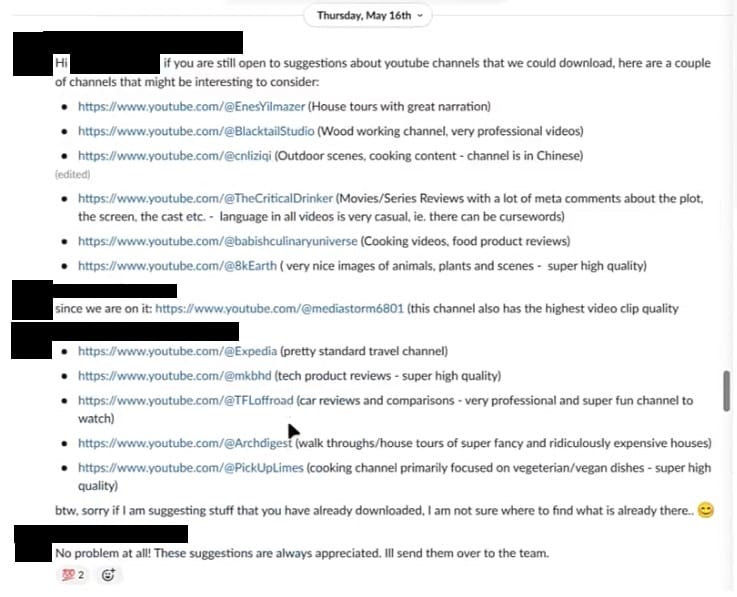
Среди популярных YouTube-каналов, которые сотрудники Nvidia включили в шорт-лист, - MKBHD, PickUpLimes, Architectural Digest, Expedia, Mediastorm6801, 8kEarth, The CriticalDrinker и другие.
Когда мы связались с 404 Media, и YouTube, и Netflix заявили, что соскабливание контента на их платформах для обучения моделей ИИ является явным нарушением условий предоставления услуг.
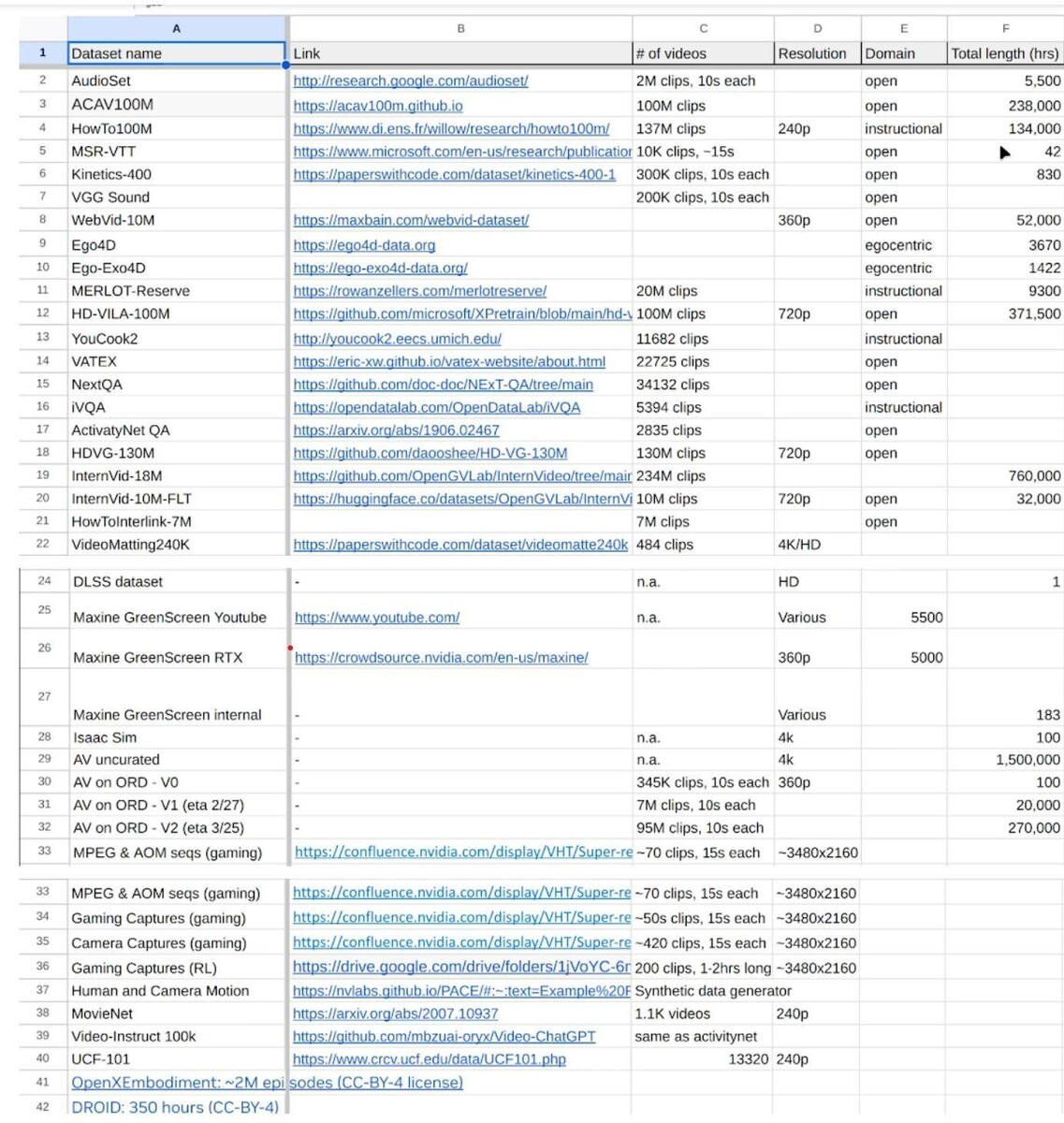
Использование данных, защищенных авторским правом, для обучения моделей ИИ все еще остается серой юридической зоной. Публичные наборы данных, такие как InternVid-10M, HD-VG-130Mи другие, основанные на миллионах видеороликов на YouTube, существуют, но они предназначены только для академических исследований, а не для коммерческих целей. Хотя в компании Nvidia работают академические исследователи, в конечном счете, полученные результаты попадут в коммерческий продукт.
На сайте есть несколько законодательных актов которые предписывают стандарты прозрачности и требуют от компаний, работающих над основополагающими моделями ИИ, сотрудничать с FTC и Бюро по авторским правам. Однако компании не всегда раскрывают свои исходные наборы данных, что значительно усложняет аудит.
Поскольку крупные ИИ-компании продолжают использовать все доступные публичные данные для обучения более эффективных моделей, законодательные изменения являются насущной необходимостью для обеспечения безопасности потребителей и защиты авторских прав.
В прошлом году газета The New York Times подала в суд на OpenAI и Microsoft за несанкционированное использование статей издания, защищенных авторским правом, для обучения моделей ИИ. В мае художники подали иск против Stability AI, Midjourney, DeviantArt и Runway AI за использование копий их работ для обучения моделей ИИ без разрешения.
YouTube становится золотой жилой для компаний, занимающихся разработкой ИИ. Недавно журнал Wired сообщил что такие крупные компании, как Apple, Nvidia, Anthropic и Salesforce, вырезали субтитры из 173 536 видеороликов на YouTube с более чем 48 000 каналов, чтобы обучить свой ИИ.
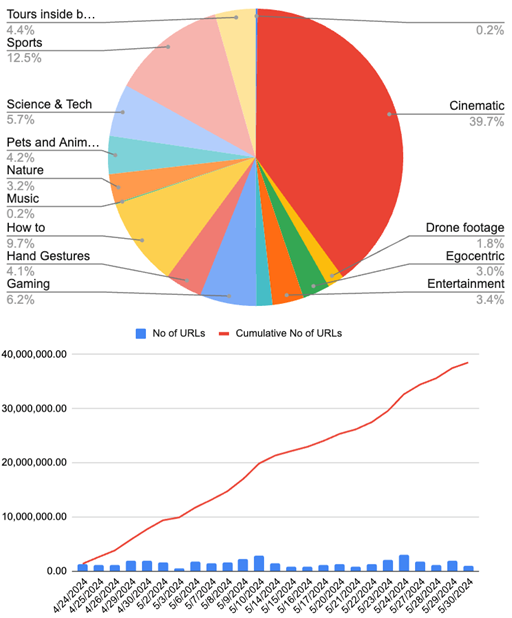
До конца мая сотрудники Nvidia объявили, что собрали 38,5 миллионов URL-адресов видео, причем большинство из них - кинематографический контент. Инженеры также добавили такие наборы данных, как Ego-Exo4D, Ego4D, HOI4Dи данные об играх с сайта GeForce Now.
В то время как Ego-Exo4D и Ego4D могут быть лицензированы как для академического, так и для коммерческого использования, HOI4D распространяется по лицензии CC BY-NC, которая специально запрещает коммерческое использование.
В настоящее время команда тренирует модель 1B с 16 узлами в каждой, а в дальнейшем планирует увеличить ее до 10B.
Компания Nvidia сообщила 404 Media по электронной почте:"Наши модели и наши исследовательские усилия полностью соответствуют букве и духу закона об авторском праве"
Между тем, Генеральный директор Nvidia Дженсен Хуанг, похоже, доволен успехами своих сотрудников.
Как сообщается, он воскликнул: "Отличное обновление. Многим компаниям приходится создавать видео FM [фундаментальные модели]. Мы можем предложить полностью ускоренный конвейер"
SCOOP from @samleecole: Leaked Slacks and documents show the incredible scale of NVidia's AI scraping: 80 years — "a human lifetime" of videos every day. Had approval from highest levels of company despite staff legal/ethical concerns:https://t.co/DydXOyffUQ
— Jason Koebler (@jason_koebler) August 5, 2024
Источник(и)
404 СМИ (требуется регистрация)














